

Some time ago I've came across an article about inserting secret text into regular messages using invisible zero-width unicode characters. Now during my work on localization SDKs, I've found quite interesting use case for it.
Background
At Tolgee we are offering localization SDKs, which enable you to insert your translated keys into web application. One of our main selling points is that we offer in-context localization out of box. In-context localization means, that when you are in development mode, you can click on any translation and change the translation directly in the app.
To make this work, our SDKs need to somehow mark where the translations are. We might just search the DOM for occurrences of translations in given language, however that won't cover more advanced cases, when we for example need to support variables in translations. Then the easiest way is to wrap each translation with span element and give it some special attribute, so then we can find it. Easy peasy, no? Well there is a catch ... what if user needs to translate texts where you can't use HTML (e.g. element attributes)? Or what if the extra span element is not acceptable?
Why is context important?
When you translate the app, it's important that you see where exactly is the translation located as pure translation from one language to another can be incorrect in many cases. So we offer in-context translation directly in the App and we want this feature to work everywhere.
Text based solution
Our original solution was in these cases insert string with our special syntax instead of the translation itself. Then we would observe whole page with MutationObserver and when we encounter this "encoded" text we find parent element and store the information about the translation and replace this message with our translation. As we found out this approach works quite well, mainly because observer is triggered before changes are rendered to the page, so this whole replacement is invisible to the user.
However, we still run into problems sometimes. We usually want to run observer only on body, so if you update e.g. page title, so then you can see text which is completely broken. Also when you use it in cases, when you need to measure the width of an element right after you change it - this will cause you problems, because the element is containing different text, so the measurements will be different. We offer the user an option to turn wrapping off, but he needs to do that explicitly and then the in-context localization doesn't work. Not ideal.
![]()
The idea of invisible marks
I think you can already see how invisible marks might be useful to us. I'll get to how it works, but for now let's just imagine, we have ability to insert invisible information to any text and then retrieve it. We can now insert secrets into every translation. Same as with regular text we can still observe the DOM for changes and when we find this "watermark" we know which translation it's containing and in-context can work anywhere.
This also opens a way for 3rd party libraries for formatting, because these invisible characters act like regular part of the text, it shouldn't be affected by regular text transformations (in theory).
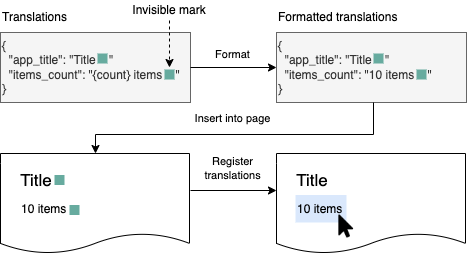
Here even if the translation doesn't get picked up by MutationObserver, the translation will still be readable and it won't influence anything visually.
How do we make text invisible?
The mechanism of invisible text is described in the mentioned article. So basically I've picked two zero width unicode characters "ZERO WIDTH NON-JOINER" (ZWN) and "ZERO WIDTH JOINER" (ZWJ), which are normally used for joining/separating multiple characters together. We can stack 8 of them together and we have a byte (ZWN = 0 and ZWJ = 1). We can literally take JavaScript string, convert it to bytes and turn it into an invisible message. This way we can even have unicode string inside an unicode string.
One caveat is that ZWJ causes two characters acting as one, so it might have effect on text surrounding it. In our use case when we use multiple ZWN and ZWJ are used in succession, only the last one is interpreted so my solution is to use one extra ZWN at the end of each byte, so it's always last and that should eliminate all side effects.
The fact that each secret byte is 9 characters long is making long texts extremely memory inefficient. So I've chose to assign each translation a number and then encode it as unicode character. This way I take an advantage of utf-8 characters which can be 1-4 bytes long, so I have effective space about 1 million combinations, which is more than enough for one page and I'll use relatively small amount of invisible characters (in most cases 9 or 18 for one key).
Can I try this?
We've just shipped Tolgee version 3, where it is as an optional setting, so you can try it yourself. We'll see if we find any issues with this approach and if not, we'll probably make it default way for wrapping translations in Tolgee.
Conclusion
We hope that this approach could allow us to use third party i18n libraries (e.g. i18next) as an alternatives to our SDKs, while keeping in-context feature working.
